 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChannelAgent-Empowered Electromagnetic Space World Model: A Case Study on Agent-Driven Channel Generation for 6G AI-Native Air Interface
May 14, 2026As sixth-generation (6G) wireless networks evolve toward increasingly heterogeneous scenarios, tasks, and service requirements, conventional artificial intelligence (AI) models remain limited in task-aware decision-making and autonomous adaptation. To address this issue, this paper first proposes a ChannelAgent-empowered electromagnetic space world model, in which wireless intelligence is organized into a closed-loop process consisting of multi-modal sensing, ChannelAgent as the intelligent core, and execution with feedback update. As a case study, agent-driven channel generation is instantiated through path loss prediction. Specifically, a task-oriented intelligent feature selection mechanism is designed by integrating reinforcement-learning-inspired policy adaptation with evolutionary search, enabling the agent to iteratively derive compact and task-suitable feature subsets according to the current scenario and performance feedback. Simulation results demonstrate superior performance in both single-scenario and multi-scenario tasks, highlighting the potential of the proposed model for autonomous, adaptive, task-oriented, and closed-loop wireless intelligence.
Learning to Predict Future-Aligned Research Proposals with Language Models
Mar 28, 2026Large language models (LLMs) are increasingly used to assist ideation in research, but evaluating the quality of LLM-generated research proposals remains difficult: novelty and soundness are hard to measure automatically, and large-scale human evaluation is costly. We propose a verifiable alternative by reframing proposal generation as a time-sliced scientific forecasting problem. Given a research question and inspiring papers available before a cutoff time, the model generates a structured proposal and is evaluated by whether it anticipates research directions that appear in papers published after the time. We operationalize this objective with the Future Alignment Score (FAS), computed via retrieval and LLM-based semantic scoring against a held-out future corpus. To train models, we build a time-consistent dataset of 17,771 papers from targets and their pre-cutoff citations, and synthesize reasoning traces that teach gap identification and inspiration borrowing. Across Llama-3.1 and Qwen2.5 models, future-aligned tuning improves future alignment over unaligned baselines (up to +10.6% overall FAS), and domain-expert human evaluation corroborates improved proposal quality. Finally, we demonstrate practical impact by implementing two model-generated proposals with a code agent, obtaining 4.17% accuracy gain on MATH from a new prompting strategy and consistent improvements for a novel model-merging method.
MAS-on-the-Fly: Dynamic Adaptation of LLM-based Multi-Agent Systems at Test Time
Feb 14, 2026Large Language Model (LLM)-based multi-agent systems (MAS) have emerged as a promising paradigm for solving complex tasks. However, existing works often rely on manual designs or "one-size-fits-all" automation, lacking dynamic adaptability after deployment. Inspired by how biological systems adapt, we introduce MASFly, a novel multi-agent framework enabling dynamic adaptation at test time. To adapt system generation, MASFly employs a retrieval-augmented SOP instantiation mechanism that leverages a self-constructed repository of successful collaboration patterns, enabling the LLM to assemble customized MASs for new queries. For adaptive execution, MASFly incorporates an experience-guided supervision mechanism, where a dedicated Watcher agent monitors system behaviors with reference to a personalized experience pool and provides real-time interventions. Extensive experiments demonstrate that MASFly achieves state-of-the-art performance, most notably a 61.7% success rate on the TravelPlanner benchmark, while exhibiting strong task adaptability and robustness.
Step 3.5 Flash: Open Frontier-Level Intelligence with 11B Active Parameters
Feb 11, 2026We introduce Step 3.5 Flash, a sparse Mixture-of-Experts (MoE) model that bridges frontier-level agentic intelligence and computational efficiency. We focus on what matters most when building agents: sharp reasoning and fast, reliable execution. Step 3.5 Flash pairs a 196B-parameter foundation with 11B active parameters for efficient inference. It is optimized with interleaved 3:1 sliding-window/full attention and Multi-Token Prediction (MTP-3) to reduce the latency and cost of multi-round agentic interactions. To reach frontier-level intelligence, we design a scalable reinforcement learning framework that combines verifiable signals with preference feedback, while remaining stable under large-scale off-policy training, enabling consistent self-improvement across mathematics, code, and tool use. Step 3.5 Flash demonstrates strong performance across agent, coding, and math tasks, achieving 85.4% on IMO-AnswerBench, 86.4% on LiveCodeBench-v6 (2024.08-2025.05), 88.2% on tau2-Bench, 69.0% on BrowseComp (with context management), and 51.0% on Terminal-Bench 2.0, comparable to frontier models such as GPT-5.2 xHigh and Gemini 3.0 Pro. By redefining the efficiency frontier, Step 3.5 Flash provides a high-density foundation for deploying sophisticated agents in real-world industrial environments.
Rethinking the Reranker: Boundary-Aware Evidence Selection for Robust Retrieval-Augmented Generation
Feb 03, 2026Retrieval-Augmented Generation (RAG) systems remain brittle under realistic retrieval noise, even when the required evidence appears in the top-K results. A key reason is that retrievers and rerankers optimize solely for relevance, often selecting either trivial, answer-revealing passages or evidence that lacks the critical information required to answer the question, without considering whether the evidence is suitable for the generator. We propose BAR-RAG, which reframes the reranker as a boundary-aware evidence selector that targets the generator's Goldilocks Zone -- evidence that is neither trivially easy nor fundamentally unanswerable for the generator, but is challenging yet sufficient for inference and thus provides the strongest learning signal. BAR-RAG trains the selector with reinforcement learning using generator feedback, and adopts a two-stage pipeline that fine-tunes the generator under the induced evidence distribution to mitigate the distribution mismatch between training and inference. Experiments on knowledge-intensive question answering benchmarks show that BAR-RAG consistently improves end-to-end performance under noisy retrieval, achieving an average gain of 10.3 percent over strong RAG and reranking baselines while substantially improving robustness. Code is publicly avaliable at https://github.com/GasolSun36/BAR-RAG.
MoCo: A One-Stop Shop for Model Collaboration Research
Jan 29, 2026Advancing beyond single monolithic language models (LMs), recent research increasingly recognizes the importance of model collaboration, where multiple LMs collaborate, compose, and complement each other. Existing research on this topic has mostly been disparate and disconnected, from different research communities, and lacks rigorous comparison. To consolidate existing research and establish model collaboration as a school of thought, we present MoCo: a one-stop Python library of executing, benchmarking, and comparing model collaboration algorithms at scale. MoCo features 26 model collaboration methods, spanning diverse levels of cross-model information exchange such as routing, text, logit, and model parameters. MoCo integrates 25 evaluation datasets spanning reasoning, QA, code, safety, and more, while users could flexibly bring their own data. Extensive experiments with MoCo demonstrate that most collaboration strategies outperform models without collaboration in 61.0% of (model, data) settings on average, with the most effective methods outperforming by up to 25.8%. We further analyze the scaling of model collaboration strategies, the training/inference efficiency of diverse methods, highlight that the collaborative system solves problems where single LMs struggle, and discuss future work in model collaboration, all made possible by MoCo. We envision MoCo as a valuable toolkit to facilitate and turbocharge the quest for an open, modular, decentralized, and collaborative AI future.
Thinking Traps in Long Chain-of-Thought: A Measurable Study and Trap-Aware Adaptive Restart
Jan 17, 2026Scaling test-time compute via Long Chain-of-Thought (Long-CoT) significantly enhances reasoning capabilities, yet extended generation does not guarantee correctness: after an early wrong commitment, models may keep elaborating a self-consistent but incorrect prefix. Through fine-grained trajectory analysis, we identify Thinking Traps, prefix-dominant deadlocks where later reflection, alternative attempts, or verification fails to revise the root error. On a curated subset of DAPO-MATH, 89\% of failures exhibit such traps. To solve this problem, we introduce TAAR (Trap-Aware Adaptive Restart), a test-time control framework that trains a diagnostic policy to predict two signals from partial trajectories: a trap index for where to truncate and an escape probability for whether and how strongly to intervene. At inference time, TAAR truncates the trajectory before the predicted trap segment and adaptively restarts decoding; for severely trapped cases, it applies stronger perturbations, including higher-temperature resampling and an optional structured reboot suffix. Experiments on challenging mathematical and scientific reasoning benchmarks (AIME24, AIME25, GPQA-Diamond, HMMT25, BRUMO25) show that TAAR improves reasoning performance without fine-tuning base model parameters.
Step-DeepResearch Technical Report
Dec 24, 2025As LLMs shift toward autonomous agents, Deep Research has emerged as a pivotal metric. However, existing academic benchmarks like BrowseComp often fail to meet real-world demands for open-ended research, which requires robust skills in intent recognition, long-horizon decision-making, and cross-source verification. To address this, we introduce Step-DeepResearch, a cost-effective, end-to-end agent. We propose a Data Synthesis Strategy Based on Atomic Capabilities to reinforce planning and report writing, combined with a progressive training path from agentic mid-training to SFT and RL. Enhanced by a Checklist-style Judger, this approach significantly improves robustness. Furthermore, to bridge the evaluation gap in the Chinese domain, we establish ADR-Bench for realistic deep research scenarios. Experimental results show that Step-DeepResearch (32B) scores 61.4% on Scale AI Research Rubrics. On ADR-Bench, it significantly outperforms comparable models and rivals SOTA closed-source models like OpenAI and Gemini DeepResearch. These findings prove that refined training enables medium-sized models to achieve expert-level capabilities at industry-leading cost-efficiency.
Adaptation of Agentic AI
Dec 22, 2025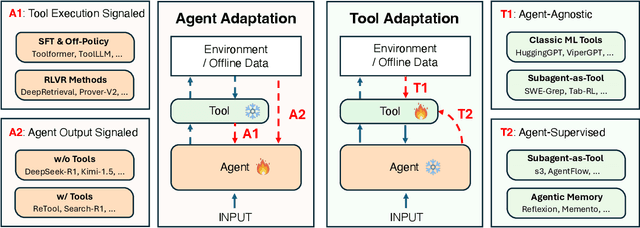
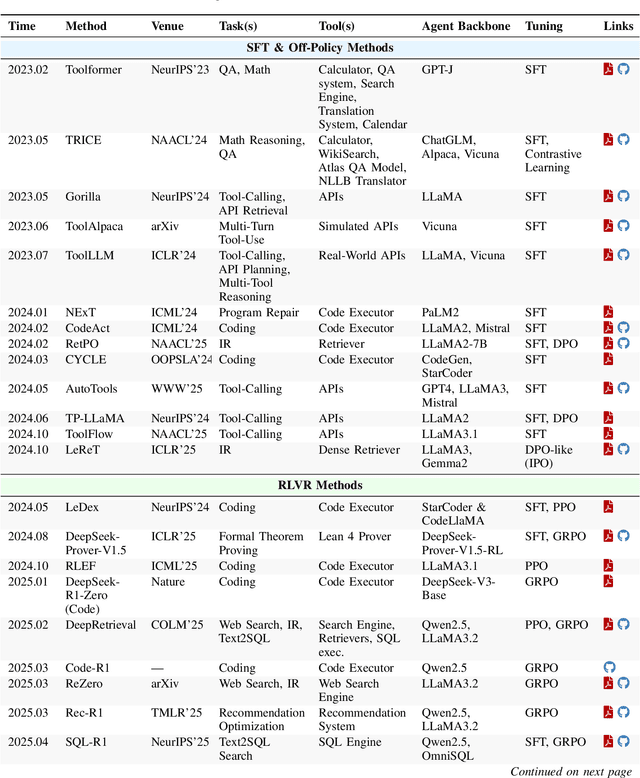
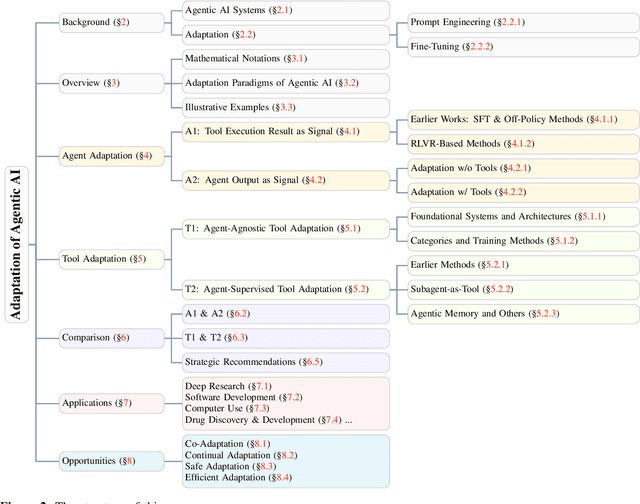
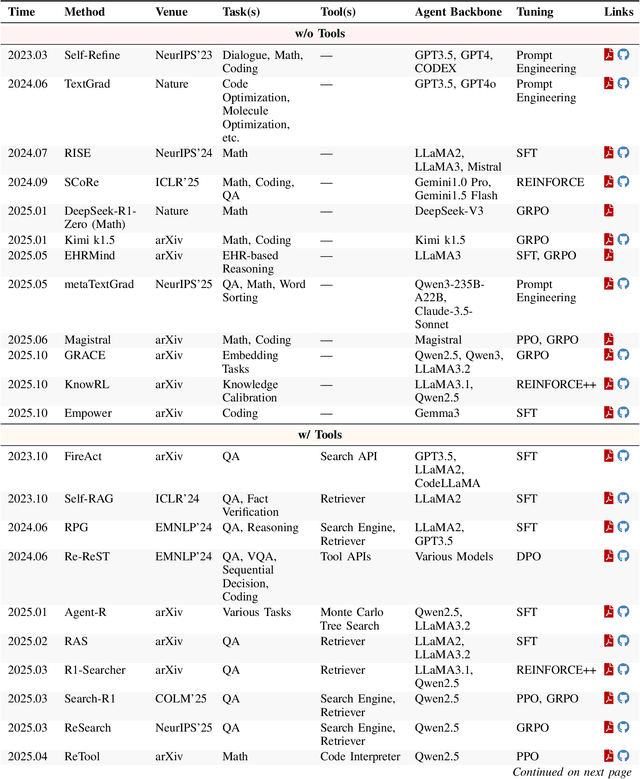
Cutting-edge agentic AI systems are built on foundation models that can be adapted to plan, reason, and interact with external tools to perform increasingly complex and specialized tasks. As these systems grow in capability and scope, adaptation becomes a central mechanism for improving performance, reliability, and generalization. In this paper, we unify the rapidly expanding research landscape into a systematic framework that spans both agent adaptations and tool adaptations. We further decompose these into tool-execution-signaled and agent-output-signaled forms of agent adaptation, as well as agent-agnostic and agent-supervised forms of tool adaptation. We demonstrate that this framework helps clarify the design space of adaptation strategies in agentic AI, makes their trade-offs explicit, and provides practical guidance for selecting or switching among strategies during system design. We then review the representative approaches in each category, analyze their strengths and limitations, and highlight key open challenges and future opportunities. Overall, this paper aims to offer a conceptual foundation and practical roadmap for researchers and practitioners seeking to build more capable, efficient, and reliable agentic AI systems.
PIGEON: VLM-Driven Object Navigation via Points of Interest Selection
Nov 17, 2025



Navigating to a specified object in an unknown environment is a fundamental yet challenging capability of embodied intelligence. However, current methods struggle to balance decision frequency with intelligence, resulting in decisions lacking foresight or discontinuous actions. In this work, we propose PIGEON: Point of Interest Guided Exploration for Object Navigation with VLM, maintaining a lightweight and semantically aligned snapshot memory during exploration as semantic input for the exploration strategy. We use a large Visual-Language Model (VLM), named PIGEON-VL, to select Points of Interest (PoI) formed during exploration and then employ a lower-level planner for action output, increasing the decision frequency. Additionally, this PoI-based decision-making enables the generation of Reinforcement Learning with Verifiable Reward (RLVR) data suitable for simulators. Experiments on classic object navigation benchmarks demonstrate that our zero-shot transfer method achieves state-of-the-art performance, while RLVR further enhances the model's semantic guidance capabilities, enabling deep reasoning during real-time navigation.